[민구/2nd meetup] Extended ML 키워드 조사
머신러닝 이론 회귀와 분류의 공통점과 차이점 회귀와 분류는 지도학습(Supervised)의 종류인데 분류(Classification)이란 주어진 데이터를 정해진 카테고리에 따라 분류하는 방법이다. 예시로는 스팸분류가 있는데 이메일은 스팸메일이거나 정상적인 ...

Artificial Intelligence and computer gaming분야를 개척한 Arthur Samuel이
머신 러닝이란 용어를 처음 사용함.
아서에 따르면 머신러닝은 명시적으로 프로그래밍 되지 않은 컴퓨터들에게 학습을
할 수 있는 능력을 주는 것이라고 한다.

Machine Learning은 Traditional Programming과 다르게 data와 함께 로직(Program)을 주는 것이 아니라
Output을 주어 스스로 학습하게 하고, 기계가 스스로 로직을 만들게 하는 것이다.
## ML(머신 러닝)
앞에서 말하였듯이 머신 러닝은 모든 답들이 프로그래밍 되어 있지 않은
컴퓨터들에게 학습을 할 수 있는 능력을 주는 것이다.
그리고, 기계에게 이러한 배울 수 있는 능력을 줌으로서 사람과 더욱 비슷하게 해준다.
## Rule-based Learning(규칙 기반 학습)
규칙 기반학습은 사람이가지고 있는 지식(규칙)들을 시스템에 코딩하여 사용하는 것이어서
오로지 저장된 내용만 처리할 수 있다.
따라서, 저장되지 않은 내용에 관련된 문제를 다루지 못한다. 또한, 이러한 방식은 시간과 비용이 많이 든다.
AI는 기계가 사람의 지능을 얻는 과정을 시행 하는 것이다.
이러한 과정들은 학습(learning), 추론(reasoning), 자가 조정(self-correction)이 있다.
또한, AI는 약하거나(weak) 강한 것으로(strong) 분류될 수있다.
약한(weak) AI는 좁은 범위의 AI로, 특정한 일을 수행하기 위해서 디자인 된 것이다.
그 예시로는 Virtual personal assistnats인 Siri가 있다.
강한(Strong) AI는 artifucialgeneralintelligence로 알려져있으며 일반적인 사람의인지를 가지고있는 AI 시스템이다.
익숙하지 않은 일을 받았을때 강한(Strong) AI는 사람의 개입없이 방법을 찾을 수 있다.
ML은 데이터를 분류하는 방법으로, 자동적으로 분류하는 모델을 만드는 것이다.
이것은 AI의 한 부분으로 사람의 개입을 최소화 하여 시스템들이 데이터로 부터 학습하고,
패턴을 분류하며 결정 내릴 수 있다는 생각을 기반으로 한다. ## - Deep Learning
Deep Learning은 머신러닝의 한부분이다. 이것은 네트워크들을 가지는 데 이 네트워크들은 구조화 되지 않고,
분류 되지 않은 데이터들로 부터 자율적인 학습을 한다.
Deep learning은 또한, neural learning, deep neural network로 알려져 있기도 한다.
딥러닝은 일반적으로 구조화 되지 않은 빅데이터를 분류하기 위해 사용된다.
또한, 딥러닝은 계급에 따른 인공 신경망(hierarchical level of artificial neural networks)를 사용한다.
이러한 인공 신경망들은 사람의 뇌처럼 구조화 되어있며 마치 거미줄처럼 모든 뉴런 노드들이 연결되어 있다.
Classification은 Supervised Learning의 일종으로, 기존에 존재하는 데이터와 카테고리의 관계를 학습하여
새로 관측된 데이터의 카테고리를 판별한다.
Calssification에는 Decision Tree, Regression Tree, Naïve Bayes Classifier, KNN등이 있다.
Decision Tree는 말그대로 루트에서 부터 적절한 노드를 선택하여 진행하다가 최종 결정을 내리게 되는 모델이다.
Regression Tree는 Yes or no로 단 두개인 선택지가 아니라 실제 여러개의 선택지를 output으로 가지는 모델이다.
Naïve Bayes Classifier는 일종의 확률 모델이다.
어떠한 데이터를 설명하는 특징들이 셀 수 없을 정도로 많다고 가정하였을때
Naïve Bayes는 이 모든 특징들이 서로 독립적이며 같은 분포를 가진다는 가정을 가지고 분류하는것이다.
마지막으로 KNN은 가까운 데이터는 같은 분류일 가능성이 크다고 가정하고 새로운 데이터가 들어오면
그 데이터와 가장 비슷한 임의의 데이터를 뽑아 뽑은 데이터들의 분류를 관측하고
그중 가장 많은 분류에 새로운 데이터를 넣는 방식이다. ## 2. Clustering
Clustering은 Unsupervised Learning의 일종으로 분류된 데이터 없이
주어진 데이터들을 가장 잘 설명하는 Cluster를 찾는 문제이다. 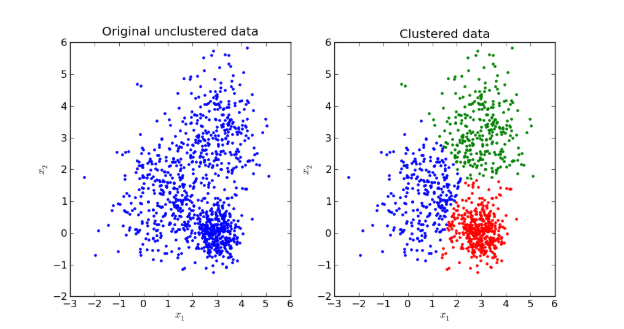
Clustering을 하는 방법중 하나인 K-means는 클러스터 내부에 속한 데이터들이 서로 가깝다고 정의하고
가장 가까운 내부 거리를 가지는 클러스터를 고르는 것이다. 이때 각각의 클러스터들 마다 중심이 존재하고
각각의 데이터가 그 중심과 얼마나 가까운거를 cost로 정의한다.
이때, K-means는 이렇게 정의된 cost를 가장 줄이는 클러스터를 찾는 알고리즘이다.
다음으로 GMM(Gaussan Mixture Model)이 있다.
GMM은 데이터가 K개의 가우시안 모형으로 구성되어 있다고 하였을때, 가장 데이터를 잘 설명하는
K개의 평균과 공분산을 찾는 알고리즘이다. ## 3. Regression
Regression은 Supervised Learning으로 선형회귀를 이용한 방식이다.
회귀 모델을 설계할려면 가설, 손실함수, 경사 강하 알고리즘이 필요하다.
가설은 어떠한 값들을 이어주는 그래프를 그려서 값들을 추측해보는 것이다.
손실 함수는 가설로 만들어진 그래프를 수식으로 만든 것을 실제 값과의 오차를 계산하기 위해 사용되는이다.
마지막으로 경사 강하 알고리즘은 경사를 따라서 내려가며 최저 Cost값(중심점)을 찾는 것이다.
이렇게 가장 낮은 Cost값을 가지는 점의 값을 통해 임의의 값 넣었을때의 결과값을 확인할 수 있게된다. ## 4. Sequence
Sequence는 다른 종류의 Supervised Learning문제와 다르다.
Sequence는 일련의 트레이닝 모델들을 관찰하여 다음에 나올 값을 예상하는 방법이다.
Prediction은 계속 데이터에 따른 결과값을 학습하여 새로운 데이터와 비슷한 특정한 값을 이용해
예측하여 적용하는 것이다.
이는 계속된 데이터를 기반으로 예측하여 결과를 맞추기 때문에 높은확률로 맞아 떨어진다.
Interaction bias는 사용자가 어떤 것에 대해 편견을 가지고 있는데 이게 알고리즘과 연관이 되있는 것이다.
예를들어 구글이 유저들에게 신발을 그려라고 하면 사용자들은 남성의 신발만 그리기때문에
하이힐 같은 여성의 신발은 알지 못한다는 것이다.
알고리즘은 성, 인종, 수익등등에 대해서 불분명하게 생각(idea)들과 연관되어있다.
예를 들어 Doctor는 남성과 연관되어있다는 생각이다.
왜냐하면 저장된 사진들이 보통 남성을 가리키고 있기 때문이다. ## 3. Selection bias
Selection bias는 알고리즘을 트레이닝 하는데 사용된 데이터는 한 집단을 높게 평가한다.
알고리즘을 더 잘 작동하기 위해서 다른 집단을 희생시키면서까지.
만약, 이미지를 인지하는 것에서 오로지 백인만이 학습 되었다면
AI가 판단하는 아름다운 사람 선발대회에서 백인들이 승리할 것이다.
머신러닝 이론 회귀와 분류의 공통점과 차이점 회귀와 분류는 지도학습(Supervised)의 종류인데 분류(Classification)이란 주어진 데이터를 정해진 카테고리에 따라 분류하는 방법이다. 예시로는 스팸분류가 있는데 이메일은 스팸메일이거나 정상적인 ...
이번 회차 Keyword 머신러닝 이론 회귀와 분류의 공통점과 차이점 □ 분류(Classification) 미리 정의된, 가능성 있는 여러 class label중 하나를 예측하는 것! ◇ 이진 분류(binary clas...
What is ML?
Keywords of week 1 What is ML? ML vs Rule-based AI, ML, Deep Learning Type of ML (Classification, Clustering, Regression, Sequence Prediction) Kin...
What is ML? 기계 학습(Machine Learining)이란 무엇인가?
What is ML? 머신러닝은 인공지능의 한 분야로 컴퓨터가 학습할 수 있도록 하는 알고리즘과 기술을 개발하는 분야이다. 즉, 기계가 일일이 코드로 명시하지 않은 동작을 데이터로부터 학습하여 실행할 수 있도록 하는 알고리즘을 개발하는 연구 분야라고 할 수 있다.
What is ML? 기계학습으로 인간이 하나부터 열까지 직접 코드를 지정해 주는 것이 아닌 학습할 무언가를 기계에 주고 이걸 가지고 스스로 학습하는 기계이다.
골빈해커 3분 딥러닝(텐서플로편) https://github.com/golbin/TensorFlow-Tutorials
What is ML?