

[민구/2nd meetup] Extended ML 키워드 조사
머신러닝 이론 회귀와 분류의 공통점과 차이점 회귀와 분류는 지도학습(Supervised)의 종류인데 분류(Classification)이란 주어진 데이터를 정해진 카테고리에 따라 분류하는 방법이다. 예시로는 스팸분류가 있는데 이메일은 스팸메일이거나 정상적인 ...

가장 큰 차이점은 연속성! 공통점은 아무래도 예측하는 것?!
회귀 (Regression) 연속적인 숫자, 또는 부동소수점수 (실수)를 예측하는 것. 주식 가격을 예측하여 수익을 내는 알고 트레이딩 등이 이에 속한다.
분류 (Classification) 미리 정의된, 가능성 있는 여러 클래스 레이블(class label) 중 하나를 예측하는 것. 얼굴 인식, 숫자 판별 등이 이에 속한다.
어떤 변수에 다른 변수들이 주는 영향력을 선형적으로 분석하는 대표적인 방법.
독립 변수가 1개일 때 - 단순 선형 회귀 모델 (Simple Linear Regression) Y=β0+β1X+ϵ
독립 변수가 n개일 때 - 다중 선형 회귀 모델 (Multiple Linear Regression) Y=β0+β1X1+…+βnXn+ϵ
LSE (Least Square Estimation) error 제곱이 최소화가 되도록 계수를 찾는 방법!
정규화는 모델 복잡도에 대한 패널티(penalty) 정규화는 과적합을 예방하고 일반화 성능을 높이는 데 도움을 준다


정규화의 일종. 모델 가중치의 L1 norm(가중치 각 요소 절대값의 합)에 대해 패널티를 부과한다. 대부분의 요소값이 0인 sparse feature에 의존한 모델에서 L1 정규화는 불필요한 피처에 대응하는 가중치들을 정확히 0으로 만들어 해당 피처를 모델이 무시하도록 만든다. 다시 말해변수 선택(feauture selection) 효과가 있다.
정규화의 일종. 모델 가중치의 L2 norm의 제곱(가중치 각 요소 제곱의 합)에 대해 패널티를 부과한다. L2 정규화는 아주 큰 값이나 작은 값을 가지는 outlier 모델 가중치에 대해 0에는 가깝지만 0은 아닌 값으로 만든다. L2 정규화는 선형 모델의 일반화 능력을 언제나 항상 개선시킨다.
원-핫 인코딩은 단어 집합의 크기를 벡터 차원으로 하고, 표현하고 싶은 단어의 인덱스에 1의 값을 부여하고 다른 인덱스에는 0을 부여하는 단어의 벡터 표현 방식이다. 이렇게 표현된 벡터를 원-핫 벡터(One-hot Vector)라고 한다.
#원-핫 인코딩 예시
[[0. 0. 1. 0. 0. 0. 0. 0.] #인덱스 2의 원-핫 벡터
[0. 0. 0. 0. 0. 1. 0. 0.] #인덱스 5의 원-핫 벡터
[0. 1. 0. 0. 0. 0. 0. 0.] #인덱스 1의 원-핫 벡터
[0. 0. 0. 0. 0. 0. 1. 0.] #인덱스 6의 원-핫 벡터
[0. 0. 0. 1. 0. 0. 0. 0.] #인덱스 3의 원-핫 벡터
[0. 0. 0. 0. 0. 0. 0. 1.]] #인덱스 7의 원-핫 벡터
활성함수란, 네트워크에 비선형성(nonlinearlity)을 추가하기 위해 사용됨

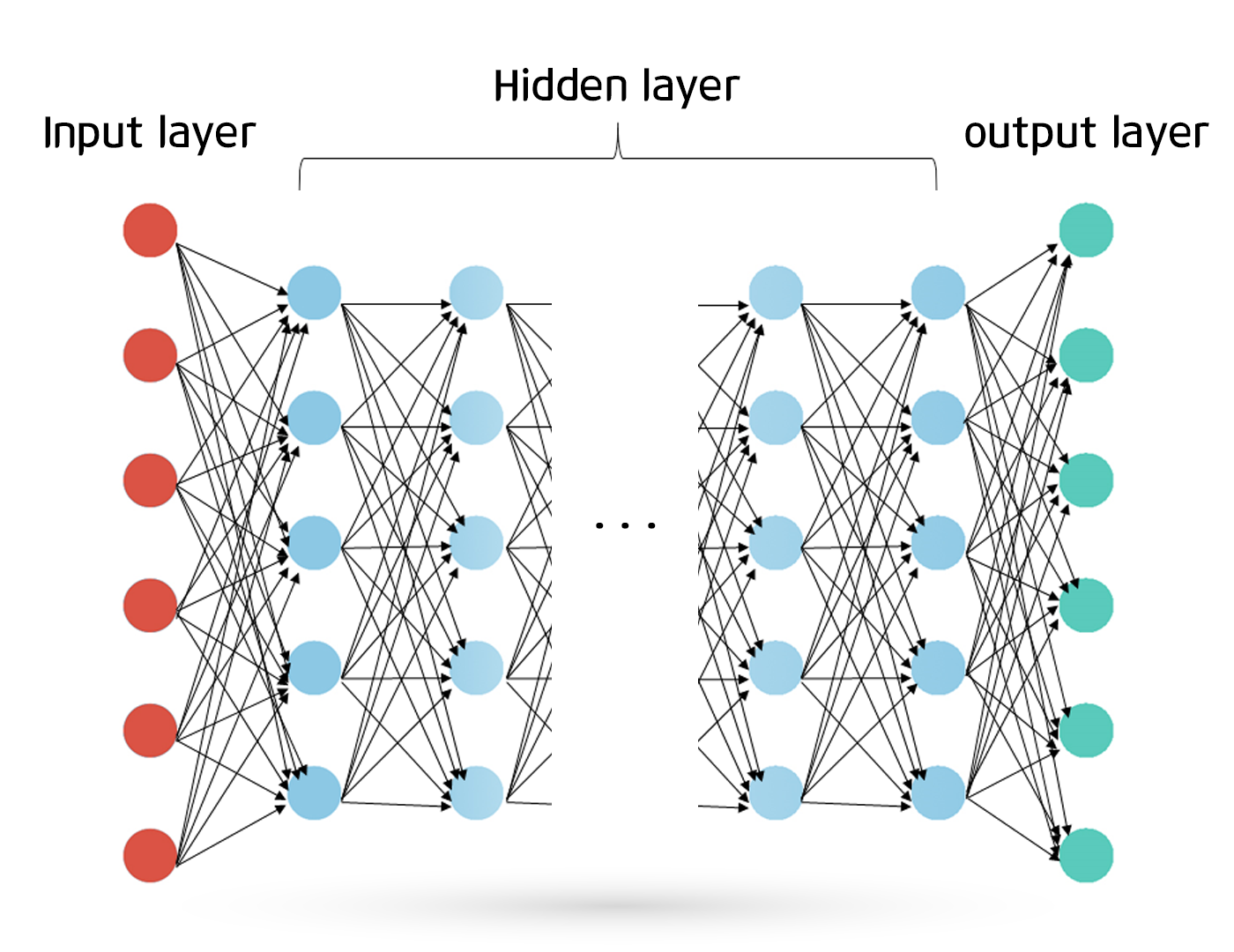
신경망은 생물학 모델을 바탕으로한 컴퓨팅의 한 형태로서, layer 로 조직된 많은수의 처리 요소로 구성된 수학 모델, 외부입력에 반응하여 동적으로 정보를 처리하는 많은 간단하지만 고도로 상호 연결된 처리요소로 구성된 컴퓨터 시스템 등으로 정의된다.

뉴런은 함수와 같다. 몇 가지 입력값을 넣으면 촤라락 계산해서 결과 값이 나온다.
위 사진은 인공 뉴런을 설명합니다. 왼쪽에 보이는 값은 두 입력값과 바이어스(bias) 값이 더해진 것입니다. 바이어스 값이 -2로 설정되어 있는 동안 입력값은 1 또는 0입니다.
두 입력은 7과 3이라는 weight라 불리는 값들로 곱해집니다.
최종적으로 이 값들을 바이어스 값과 함께 더한 후 5라는 결과값을 내놓습니다. 이게 인공 뉴런의 입력값입니다.
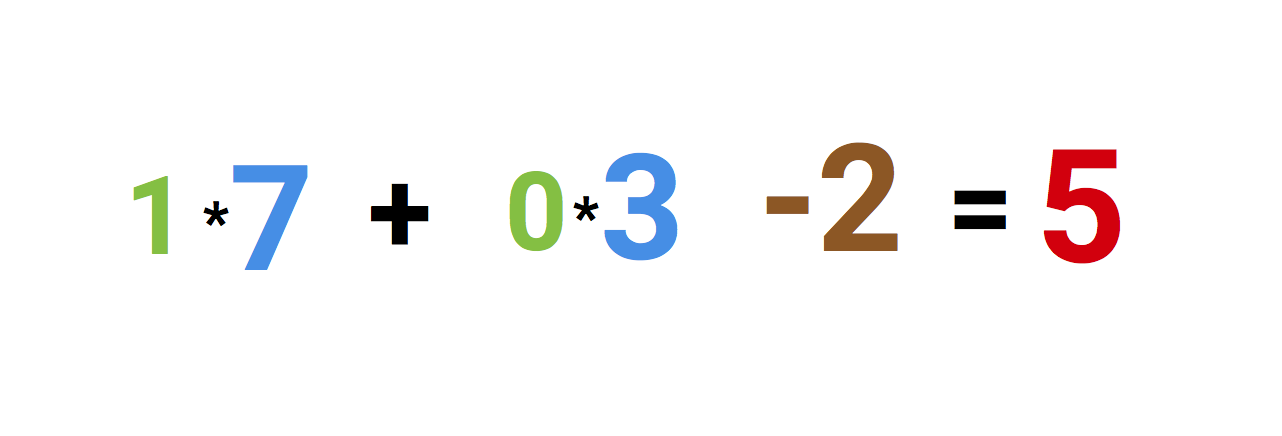
뉴런은 이 숫자들을 가지고 어떤 계산을 합니다. 지금 이 경우에는 5를 넣고 계산한 시그모이드 값은 반올림 하면 1이 나옵니다.

이 뉴런들을 네트어ㅜ크를 통해 연결한다면 전향적인(forward) 뉴런 네트워크를 가질 수 있습니다. 입력값부터 결과까지 시냅스를 통해 각각이 연결되면 위의 이미지처럼 연결된 뉴런이 된다.
https://www.youtube.com/watch?v=bxe2T-V8XRs

입력값에서 결과값이 나오기까지 뉴럴 네트워크가 동작하는 과정을 하는 것은 그닥 어렵지 않으나, 실제 데이터 샘플들을 가지고 뉴럴 네트워크가 어떻게 배우는지 이해하는 것이 좀 더 어렵다. 이 개념이 바로 역전파법! (back propagation)이다.
기실 의미하는 바는 네트워크가 예측한 것에 비해 얼마나 잘못된 것인지고, 그에 따라 얼마만큼 네트워크 weight를 조정하는 것에 달려있다.
이 과정은 거꾸로 진행된다. 네트워크가 끝나는 부분에서 시작된다. 이 과정은 네트워크가 추축하는 것이 얼마나 잘못된 것인 지를 확인하는 것이다.

입력값에 도달하기까지 weight를 조정하면서 네트워크에서 반대방향으로 진행된다.
import numpy as np
#sigmoid function
def nonlin(x, deriv=False):
if(deriv==True):
return x*(1-x)
return 1/(1+np.exp(-x))
#input dataset
X = np.array([0, 0, 1], [0, 1, 1], [1, 0, 1], [1, 1, 1])
# 결과 데이터 값
y = np.array([0, 0, 1, 1]).T
# 계산을 위한 시드 설정
# 실험의 편의를 위해 항상 같은 값이 나오게 한다.
np.random.seed(1)
# weights를 랜덤적으로 mean of 0으로 초기화하자.
syn0 = 2*np.random.random((3,1)) -1
for iter in range(10000):
#forward propagation
l0 = X
l1 = nonlin(np.dot(l0, syn0))
# 우리가 얼마나 놓쳤는지?
l1_error = y - l1
# 우리가 놓친 것과 l1의 시모이드 경사와 곱하기
l1_delta = l1_error * nonlin(l1, True)
# Weight 업뎃
syn0 += np.dot(l0.T, l1_delta)
print("Output After Traning")
print(l1)
| 변수 | 변수에 관한 설명 |
|---|---|
| X | 각각의 행들이 트레이닝 샘플인 입력 데이터 행 |
| y | 각각의 행들이 트레이닝 샘플인 결과 데이터 행 |
| l0 | 네트워크의 첫 번째 층. 입력 데이터값들을 특징화한다. |
| l1 | 네트워크의 두 번째 층. 보통 히든 레이어으로 알려져 있다. |
| syn0 | weight들의 첫번째 레이어인 시냅스 0로 l0과 l1를 연결시킨다. |
| * | 벡터의 원소별 곱셈(Elementwise multiplication). 같은 크기의 두 벡터의 상응하는 값들을 대응시켜 곱한 같은 크기의 벡터를 반환한다. |
| - | 벡터의 원소별 뺄셈(Elementwise subtraction). 같은 크기의 두 벡터의 상응하는 값들을 대응시켜 뺀 벡터를 반환한다. |
| x.dot(y) | x, y가 벡터라면, 벡터의 내적(dot product)이다. 둘 다 행라면, 행의 곱이고, 만약 오직 하나만이 행라면, 벡터-행 곱이다. |
https://ddanggle.github.io/11lines
머신러닝 이론 회귀와 분류의 공통점과 차이점 회귀와 분류는 지도학습(Supervised)의 종류인데 분류(Classification)이란 주어진 데이터를 정해진 카테고리에 따라 분류하는 방법이다. 예시로는 스팸분류가 있는데 이메일은 스팸메일이거나 정상적인 ...
이번 회차 Keyword 머신러닝 이론 회귀와 분류의 공통점과 차이점 □ 분류(Classification) 미리 정의된, 가능성 있는 여러 class label중 하나를 예측하는 것! ◇ 이진 분류(binary clas...
What is ML?
Keywords of week 1 What is ML? ML vs Rule-based AI, ML, Deep Learning Type of ML (Classification, Clustering, Regression, Sequence Prediction) Kin...
What is ML? 기계 학습(Machine Learining)이란 무엇인가?
What is ML? 머신러닝은 인공지능의 한 분야로 컴퓨터가 학습할 수 있도록 하는 알고리즘과 기술을 개발하는 분야이다. 즉, 기계가 일일이 코드로 명시하지 않은 동작을 데이터로부터 학습하여 실행할 수 있도록 하는 알고리즘을 개발하는 연구 분야라고 할 수 있다.
What is ML? 기계학습으로 인간이 하나부터 열까지 직접 코드를 지정해 주는 것이 아닌 학습할 무언가를 기계에 주고 이걸 가지고 스스로 학습하는 기계이다.
골빈해커 3분 딥러닝(텐서플로편) https://github.com/golbin/TensorFlow-Tutorials
What is ML?